





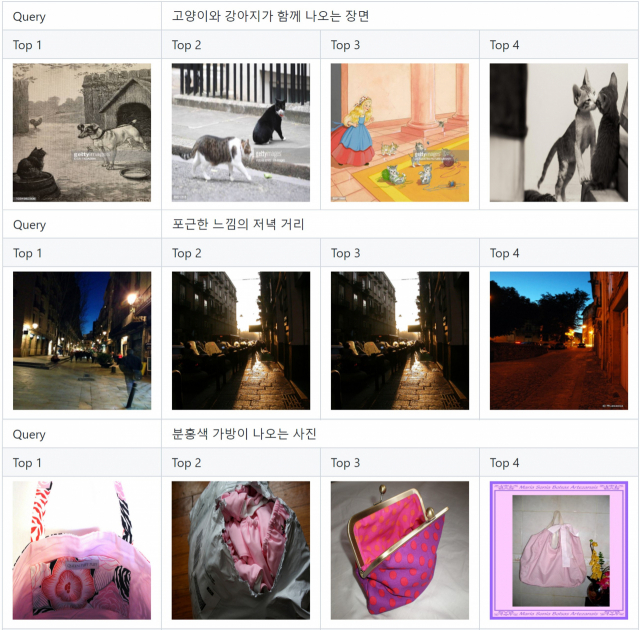
인공지능(AI)이 고양이와 강아지가 함께 나오는 장면과 같은 텍스트를 인간 수준으로 이해하고, 적합한 이미지를 자동으로 결합하는 모델이 공개됐다.
한국전자기술연구원(KETI)은 AI 연구에 활용 가능한 최첨단 사전학습 모델 ‘VL-KE-T5’를 선보이고 무료로 배포한다고 16일 밝혔다.
사전학습 모델은 자기지도학습을 통해 대용량 데이터로부터 범용적 의미를 미리 학습하는 인공지능 기법이다. 높은 구축비용이 필요한 학습 데이터 기반의 학습을 최소화하고 비교적 쉽게 확보 가능한 원시 데이터를 학습에 활용해 다양한 인공지능 문제에 높은 성능을 보여주고 있다.
‘VL-KE-T5’ 모델은 과학기술정보통신부와 정보통신기획평가원, 정보통신산업진흥원의 지원으로 개발됐다.
관련기사
‘VL-KE-T5’는 지난해 4월 KETI가 구축해 무상 공개했던 언어(한국어·영어) 기반 사전학습 모델인 ‘KE-T5’와 구글이 공개한 시각 기반 사전학습 모델인 ‘ViT’의 의미 정보를 정렬시킨 모델이다. KETI는 언어·시각 기반 사전학습 모델을 인공지능이 동시에 처리할 수 있도록 두 모델의 상이한 의미 표현을 동일한 의미 단위로 정렬시켰다.
KETI 관계자는 “인간은 영상과 언어 정보를 연계해서 정보를 이해하고 표현하는 반면 지금까지의 인공지능은 영상과 언어를 분리한 단일 지능으로 연구되고 있다”며 “KETI는 영상 데이터와 언어 데이터 간의 의미적 차이를 대조 학습시켜 상이한 모델을 연계했다”고 설명했다.
‘VL-KE-T5’는 영상 정보와 언어 정보의 연계 처리가 가능한 복합지능이다. 한국어와 영어를 동시에 지원해 두 언어 기반의 업무처리가 모두 가능하다는 장점을 지니고 있다. 이 모델은 오픈소스 라이센스(Apache 2.0)에 따라 자유롭게 활용 및 배포가 가능하기 때문에 대학이나 연구소, 중소기업 등 국내 인공지능 연구 전반에 확산이 기대된다.
이번 연구를 주도한 신사임 KETI 인공지능연구센터장은 “KETI 인공지능연구센터는 앞으로도 인공지능 사전학습 및 복합지능 연구에 필요한 핵심 인프라를 지속적으로 공개할 것”이라며 “향후 관련 분야 중소기업의 기술 사업화에도 지원을 아끼지 않겠다”고 밝혔다.
< 저작권자 ⓒ 서울경제, 무단 전재 및 재배포 금지 >
 mykj@sedaily.com
mykj@sedaily.com






































