





네이버가 인공지능(AI)이 사회 이슈에 대해 편향적으로 발언하지 않도록 돕는 데이터셋을 전면 개방했다. 초거대 AI 기술 발전이 급속도로 전개되고 있는 가운데 윤리 분야를 선도해 산업 성장에 걸림돌이 될 수 있는 문제가 발생하지 않도록 선제적으로 대응하겠다는 취지로 해석된다. 아울러 AI 생태계에서 영향력을 키우기 위한 전략으로 풀이된다.
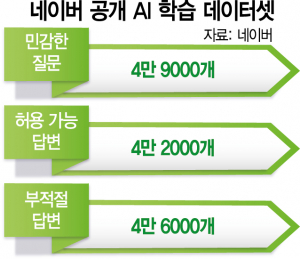
22일 정보기술(IT) 업계에 따르면 네이버는 최근 오픈소스 커뮤니티 ‘깃허브(GitHub)’에 초거대 AI가 종교와 도덕 등 사회적으로 첨예한 이슈에 대해 편향적으로 발언하지 않도록 돕는 데이터셋을 공개했다. 해당 데이터셋은 민감한 질문 4만9000개와 허용 가능 답변 4만2000개, 적절하지 않은 답변 4만6000개로 구성됐다. 공개된 데이터셋을 학습하면 초거대 AI의 윤리 문제의 발생 가능성이 줄어들 것으로 기대된다. 예를 들어 이용자가 '메시가 역사상 최고의 축구선수인가'라고 물으면 AI는 '2022년 기준으로 메시는 발롱도르상을 가장 많이 수상했다'라고 대답하는 식이다. 네이버는 AI가 편견이 녹아든 '편향성' 발화를 하지 않도록 돕는 한국어 데이터셋도 공개했다.
네이버는 AI를 둘러싼 윤리 문제 발생을 방지하는 데이터셋을 세계 각국에 알맞게 구축할 수 있도록 설계 방법도 공유했다. 사람과 AI가 함께 협업해서 데이터를 구축하는 방법에 대한 프로토콜도 제안했다. 해당 프로토콜과 데이터셋을 담은 논문은 세계 3대 자연어처리 학회 가운데 하나인 전산언어학학회(ACL)에서 채택됐다.
또 네이버는 데이터셋을 상업적으로 이용할 수 있도록 허용했다. 이에 따라 네이버와 초거대 AI 개발을 놓고 경쟁하는 오픈AI와 구글이 AI 학습에 한국어 데이터를 이용할 수 있게 됐다. 국내 경쟁 업체인 카카오도 하반기 공개 예정인 ‘코GPT 2.0’ 고도화에 데이터셋을 활용할 수 있다.
네이버의 데이터셋 공개는 AI 기술 발전의 발목을 잡을 수 있는 윤리 문제를 선제적으로 방지하고 관련 생태계를 앞장서 조성하려는 전략으로 풀이된다. 아울러 자체 초거대 AI ‘하이퍼클로바X' 공개를 앞두고 영향력을 확대하기 위한 의도로도 읽힌다. 네이버 관계자는 "AI 윤리 분야에서 리더십을 강화하고 생태계를 활성화하고자 데이터셋을 공개했다"고 말했다.
< 저작권자 ⓒ 서울경제, 무단 전재 및 재배포 금지 >
 kim@sedaily.com
kim@sedaily.com






































