





생성형 인공지능(AI) 산업을 둘러싸고 벌어지는 글로벌 기술 패권 전쟁에서 살아남으려면 우수 인재와 데이터 풀 확보가 필수조건이지만 현장에서는 이를 확보하는 것이 ‘하늘의 별따기’라는 하소연이 이어진다. 글로벌 6위까지 올라온 국내 AI 기술 경쟁력을 유지하고 주도권을 확보하기 위해서는 기업들이 관련 인재를 원활히 확보할 수 있도록 돕고 데이터 풀 구축 등에 더욱 과감한 예산 집행이 필요하다는 주장이 나온다.
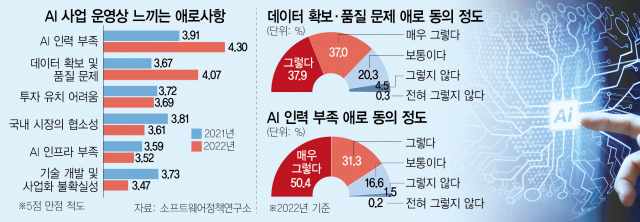
지난 4월 소프트웨어정책연구소가 발간한 ‘2022년 AI 산업 실태조사’에 따르면 지난해 AI 사업 과정에서 인력 부족을 경험하고 있는 사업체는 전체 응답 기업의 81.7%로 나타났다. 직전 연도(71.2%) 보다 10%포인트 넘게 상승했다. 지난해 11월 챗GPT가 공개된 후 AI 분야 중에서도 특히 자연어 처리(NLP) 분야에 특화된 인재에 대한 수요가 급증한 상황을 고려하면 올해 들어 인력 수급 불일치는 더욱 커졌을 것으로 추정된다.
고급 인력 공급이 제한적인 상황에서 수요가 폭발하다 보니 급기야 국내 주요 AI 기업들 사이에서 치열한 인력 쟁탈전이 벌어지고 있다. 네이버클라우드는 지난 6월 SK텔레콤을 상대로 ‘자사 AI 인력을 뺴가지 말라’는 경고성 내용증명을 보낸 것이 대표적이다.
국내 인재 수급만으로는 글로벌 빅테크와 경쟁하는데 한계를 느낀 국내 기업들은 해외 인력 유치로 눈을 돌리고 있지만 이 역시 녹록치 않은 상황이다. 취업 비자를 통해 해외 인재를 유치하고 싶지만 수급이 원활치 않다. 구글이 아시아 인재를 50%까지 확보해나가며 기술 변화에 대응해나가는 모습과 대조적이다. 업계의 한 관계자는 “국내 AI 인력 풀이 매우 협소하다"면서 "영국이 기술 분야 우수 인재를 유치하기 위해 최대 5년 간 체류가 가능한 ‘탤런트 비자’를 제공하는 것처럼 파격적인 조치가 나와야 한다”고 말했다.
전문가들은 글로벌 생성형 AI 기술 경쟁이 분초를 다툴 정도로 치열한 만큼 특정 분야에 대해 기업들이 글로벌 인재 등을 유치할 수 있도록 정책적 지원이 필요함과 동시에 장기적으로는 국내 AI 인재들이 성장해나갈 수 있는 생태계 조성이 중요하다고 강조한다.
AI 모델 구축과 고도화의 기초 재료로 여겨지는 데이터 확보에도 많은 비용과 시간이 드는 만큼 이에 대한 지원도 과감하게 늘릴 필요가 있다. 정부는 올해 2805억 원을 들여 150종의 데이터셋을 구축하기로 했다. 데이터 라벨링에 드는 비용을 줄이는 등 재원 구조를 효율화했다지만 지난해 투입된 5797억 원에 비해 절반이나 깎인 수준이다. 빅테크와의 직접 경쟁을 위해 수천억~수조 개의 토큰을 확보해야 하는 상황에서 사업 규모를 더 늘어야 한다는 지적이 나온다. 업계의 한 관계자는 “끊어지고 분절된 메타데이터는 추천이나 검색을 위한 서비스에는 도움이 되겠지만 파운데이션 모델을 만들 때는 한 묶음으로 된 큰 분량의 데이터가 필요하다"면서 "정부에서도 논문 등을 요약한 언어 데이터를 풀어놨지만 그것으로는 파운데이션 모델을 고도화하는 비즈니스 사업자에게는 한계가 뚜렷하다”고 지적했다.
< 저작권자 ⓒ 서울경제, 무단 전재 및 재배포 금지 >

 hjin@sedaily.com
hjin@sedaily.com






































