






정보기술(IT) 시장에 관심 많으신 독자 여러분, 안녕하세요. 지난 20일 SK하이닉스에서 흥미로운 반도체 개발 소식을 발표했습니다.
HBM. 바로 고대역폭메모리에 관한 내용이었는데요. TSV와 MR-MUF 기술을 활용해 D램을 12층으로 쌓아올린 'HBM3' 24GB 제품 개발을 완료했다는 게 핵심이었습니다.
이번 기사에서는 SK하이닉스의 HBM 내부는 어떤 모양이고, 어떻게 이것을 만들었을 지에 대한 정보로 총 두 편을 준비했습니다. 우선 HBM이 각광 받는 이유를 조명하고, 2편에서는 핵심 공정과 미래 HBM 제조 기술의 키 포인트도 함께 살펴보겠습니다.
大 AI 시대, ‘진짜’ 빠르게 GPU 보조할 D램 확보하기

우선 우리는 HBM을 다루기 전에 인공지능(AI)에 관한 이야기부터 간단하게 들여다 봐야 합니다. 챗 GPT, 로봇의 사물 인식, 자율 주행. 요즘 대중들 입에 자주 오르내리는 최신 기술을 관통하는 키워드는 AI입니다. IT 기기는 ‘인공지능(AI)’을 구현하기 위해 방대한 양의 데이터를 더하고, 빼고, 나누고, 곱하면서 학습을 한 뒤 스스로 추론하는 과정을 가지죠.
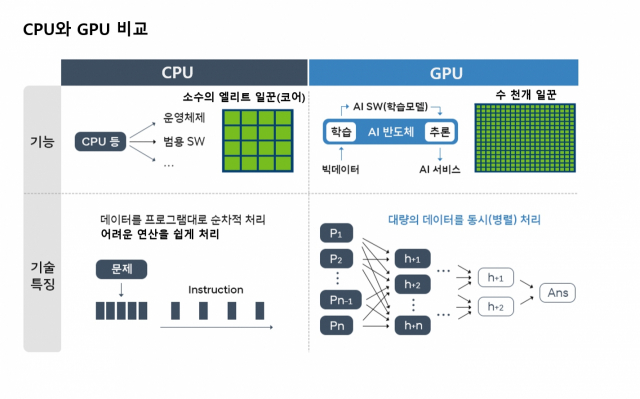
AI 기술은 반도체 업계에도 아주 큰 영향을 줬습니다. 현존하는 칩 중에서 이 작업을 가장 잘 수행하는 반도체로 그래픽처리장치(GPU)가 주목받게 된 것이 가장 굵직한 변화입니다.
GPU는 우리에게 익숙한 연산 장치인 중앙처리장치(CPU)와 완전히 특성이 다릅니다. GPU는 말 그대로 우리가 보는 넷플릭스 영상, 게임 화면 등 각종 이미지를 구현하기 위해 만든 칩입니다. CPU가 아주 어려운 연산을 빨리 풀어내는 것에 특화한 똑똑한 친구라면요. GPU는 화면에 띄울 수만 개 '픽셀(화소)' 색깔을 단번에 표현하는 역할을 합니다. CPU보다는 덜 똑똑한 일꾼들이 상대적으로 단순한 정보를 동시에, 빠르게 연산합니다. 이 칩이 AI 시장에서 각광받는 이유는 이렇게 '한꺼번에 연산'하는 장점 때문입니다. 1~4개 일꾼(코어)들이 ‘순차’ 연산하는 CPU보다 수천 개 일꾼들이 일제히 움직이는 GPU가 방대한 양의 ‘간단’ 정보를 연산해야 하는 AI 시장에서 훨씬 효율적이라는 거죠. GPU 시장 1위 엔비디아가 AI 시장 최강자로 떠오르는 계기도 됩니다.
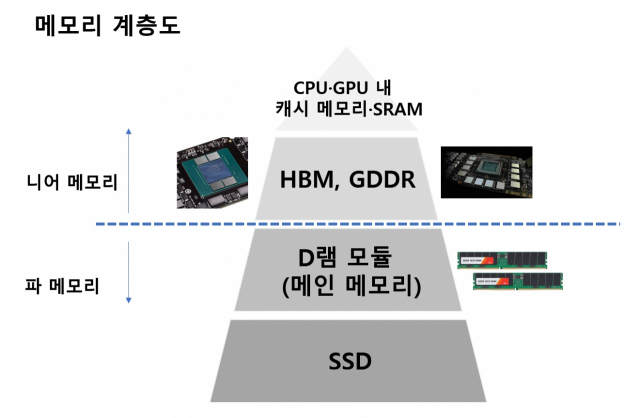
이 흐름은 메모리 시장에도 적잖은 영향을 미칩니다. 일단 우리가 상식적으로 생각하는 메모리 모듈 구조는 AI 연산에 너무 불리해졌습니다. 전통적인 구조였던 연산장치-정보를 기억하는 메모리 모듈(파·far 메모리) 사이 위치가 너무나도 멀게 느껴졌기 때문입니다. 폭발적인 양의 데이터를 빠르게 처리하려고 CPU에서 GPU까지 동원하는 마당에, 메모리 모듈이 생각만큼 속도가 빨라지고 가까워졌으면 좋겠는데 쉽지 않았죠. 그래서 각광받게 된 것이 '니어(near) 메모리'입니다. 연산 장치 가까이에서 밀착해서 정보를 누구보다 빠르게, 남들과는 다르게 '토스'해줄 수 있는 메모리가 부각되기 시작한 것이죠.
GPU에서 ‘니어 메모리’로 쓰이던 GDDR, “뭔가 살짝 아쉬워”
'니어 메모리'에서 드디어 오늘의 주인공인 HBM이 나옵니다. HBM은 High Bandwidth Memory. 즉 '고대역폭 메모리' 입니다. 뜻을 조금 더 자세하게 풀어봅시다.
대역폭의 한자는 이렇습니다. 띠 대(帶)·구역 역(域)·폭 폭(幅). 일정한 공간 안에 데이터를 교환할 수 있는 통로(띠)가 얼마나 있고, 속도는 어느 정도인지를 나타내는 말입니다. ‘고대역폭’은 한마디로 데이터 전송 속도가 일반적인 D램보다 훨씬 높다는 거죠.
자, HBM의 대역폭에 대해 조금 더 자세히 다루기 전에 우리는 또다른 니어 메모리 종류이자 HBM의 '라이벌' 격인 그래픽 D램(GDDR)의 특성부터 살펴봐야 합니다.

GDDR D램은 GPU 주변에 탑재된 ‘그래픽용 D램’ 칩입니다. 이 녀석의 장점은 속도입니다. GPU의 재빠른 이미지 연산을 돕기 위해 제작됐죠. SK하이닉스가 2017년 발표한 GDDR6 D램 스펙을 보면요. 정보가 D램으로 출입(I/O)하는 통로인 '핀' 당 정보 처리 속도는 초당 16Gb 속도입니다. 초당 160억개 0또는 1 디지털 신호를 옮기는 능력이 된다는 얘기인데요. 일반적인 서버용 D램의 핀 속도가 초당 4.8Gb인 걸 고려하면 우사인 볼트 급 속도입니다. 여기까지는 좋습니다.
그런데 여러 아쉬운 점도 보입니다. 우선 정보가 오가는 통로인 '핀'의 수인데요. 한 개 GDDR 칩에 달려있는 이 핀의 수는 32개입니다. D램 속 정보를 전달하는 속도가 아무리 빨라도 정보 이동 통로가 32개 뿐이라면, 더 많은 정보를 빠른 속도로 옮기기를 기대하는 AI 연구에서 병목 현상이 일어날 수밖에 없죠. 게다가 GPU와 GDDR 사이 거리는 D램 모듈보다 가깝기는 하지만 사진처럼 더 줄일 수 있는 여지가 있어 보입니다.
용량도 살짝 아쉽습니다. 업계 가장 최신 GDDR6 한 개 칩 용량은 2GB입니다. 통상 GPU 주변에는 그림처럼 12개 GDDR6가 놓입니다. 모든 칩을 다 끌어모은 용량이 24GB입니다. 초거대 AI 구현에 필요한 창고 용량이 24GB라니. "아, 뭔가 아쉬운데…"하는 와중에 HBM이 나타나면서 GDDR을 빠르게 대처해 나가기 시작합니다.
HBM, AI용 GPU를 측면 지원하기에 ‘안성맞춤’
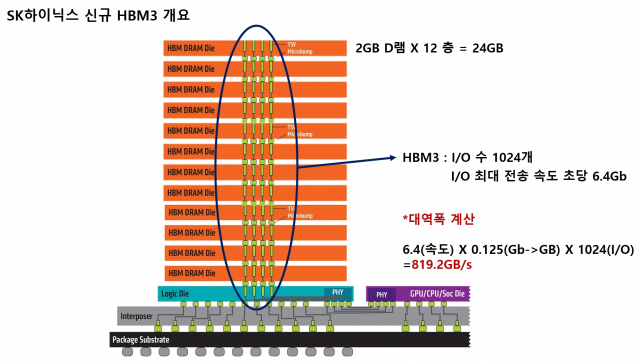
HBM. 입출구(핀) 수부터 압도하면서 AI 연구자들의 갈증을 해결합니다. HBM은 여러 개 D램을 수직으로 쌓은 뒤, 곳곳에 1024개의 구멍을 뚫어서 마치 엘리베이터같은 정보 출입 통로를 만듭니다. 전통적인 I/O 설계 방식을 따른 GDDR 한 개 칩보다 32배 많습니다. GDDR 칩이 GPU 주변에 12개 정도 위치한다고 가정하면 총 핀 수는 384개입니다. HBM은 GPU 바로 옆에 통상 4개가 위치하는데요. 4개만 놓아도 통로 수가 벌써 4096개입니다. GDDR이 아무리 데이터 전송 속도가 빨라도 384차선 도로와 4096차선 도로 중 교통 체증이 덜한 곳은 당연히 후자입니다.
게다가 HBM이 GDDR에 다소 밀리는 모습이었던 핀 당 정보 이동 속도도 더욱 빨라지고 있습니다. 2019년 SK하이닉스가 출시한 HBM2E의 속도는 초당 3.6Gb인데, 2021년 나온 HBM3는 2배 가까이 개선된 초당 6.4Gb입니다. 향후 나올 HBM4는 초당 8Gb에 육박할 것이란 전망도 있습니다. GDDR처럼 초당 16Gb 이상 속도로 무리한 정보 이동을 하지 않아서 전력 측면에서도 효율적이라고 합니다.

또 HBM은 그림처럼 GPU 칩과의 거리가 GDDR보다 가깝습니다. HBM은 GDDR과 달리 GPU와 한 개 기판 위에서 마치 한 칩처럼 움직이는 이종(異種)결합 형태로 올린 패키징 기술이 구현됐기 때문인데요. 니어(near)도 이런 ‘초’ 니어 메모리가 없죠.
그리고 마지막으로 용량. HBM의 정말 중요한 포인트가 '적층'입니다. 이번에 SK하이닉스는 세계 최초로 2GB짜리 D램을 12개 수직으로 쌓아서 24GB 용량을 만들었죠. 아까 말씀드렸던 GPU 속 GDDR6 12개를 다 합쳐야 이번 SK하이닉스 신제품 HBM3 1개 용량과 맞먹습니다. 24GB HBM이 GPU 주변에 4개 탑재되니, 96GB 용량 D램이 GPU 바로 옆에 장착되는 혁신이 일어나는 셈이네요.
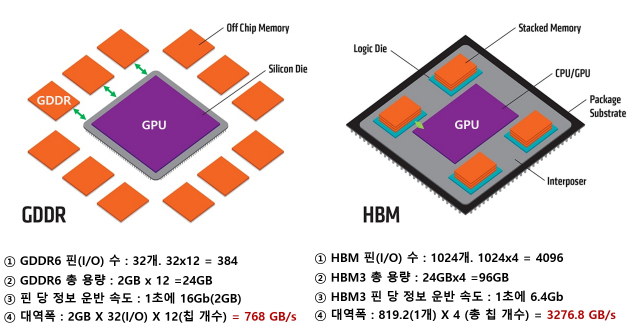
위 표에서 SK하이닉스 GDDR6(2GB/s 속도 기준) 제품 12개와 HBM3 4개 대역폭을 계산해보니 HBM이 확실히 ‘고대역폭’입니다. GDDR6 대비 4배 이상 차이입니다. 현존 업계 최대로 알려진 GDDR6 속도(초당 3GB)로 계산해봐도 3배나 빨라서 속도의 미학을 제대로 구현했습니다.
이렇게 GDDR6의 단점을 극복한 HBM은 엔비디아, AMD 등 굴지 시스템 반도체 설계 회사들을 유혹했고 이들은 여전히 큰 만족감을 나타냅니다. 각종 고급 칩에 HBM이 쓰이기 시작하면서 앞으로 AI 분야에서 애플리케이션과 사용량은 더욱 늘어날 것으로 보입니다. TSMC는 HBM을 활용한 패키징 기술을 해마다 업그레이드하고 있습니다.

물론 기능, 용량 등을 놓고 보면 니어 메모리가 파(Far) 메모리인 D램 모듈까지는 위협할 수 없지만 말이죠. AI 시장이 커가는 만큼 HBM 시장의 가능성도 점점 커지고 있습니다. 욜 디벨롭먼트에 따르면 2021년 3억2500만달러에 불과했던 HBM 시장이 2027년엔 13억2400만달러까지 성장할 것으로 보입니다.
SK하이닉스는 2013년 HBM을 처음으로 개발한 뒤 이 시장에 '진심'으로 접근하고 있습니다. AI 시장의 성장, 세계 최초로 개발했다는 자신감과 기술 노하우 등으로 떠오르는 니어 메모리 시장을 공격적으로 진입하는 분위기입니다. 최근 엔비디아 HBM 공급을 공식 발표할 만큼 자신감도 넘치죠.
이미 SK하이닉스가 생산 시작한 HBM3를 삼성전자, 미국 마이크론 등 경쟁사들은 올해 말쯤 양산할 것으로 보입니다. 이에 힘입어 SK하이닉스는 HBM 시장에서 50% 이상 점유율을 노리며 확실한 시장 리더십에 도전합니다.
특히 HBM은 기존 D램보다 2~3배 이상 더 비싼 것으로 알려지는데요. SK하이닉스 수익 구조에도 큰 도움이 될 것이란 시각도 나옵니다.
이제 HBM의 콘셉트를 알았으니까 다음 편에서는 SK하이닉스가 HBM3를 어떻게 구현했는지 공정을 자세히 살펴보겠습니다. 다음 주 2편을 기대해주세요!
< 저작권자 ⓒ 서울경제, 무단 전재 및 재배포 금지 >
 hr@sedaily.com
hr@sedaily.com






































